
Formal methods applied to hardware resulted in highly reliable systems with very few failures. Unfortunately, Fault tolerance has few practical applications to software development and system design. This is especially difficult in agile development. A little terminology before we start:
- Fault: defect, imperfection or flaw in software – commonly called “bug”
- Error: incorrect value in state. Calculation or state errors caused by the faults.
- Failure: system deviation from spec – unexpected behavior in case of a fault, system crash.
“Faults can result in errors. Errors can lead to system failures” [1]. We should try to avoid bugs and – since we can’t achieve 100 % bug free software – learn how to cope with those we missed. Additionally, a fault tolerant system should also tolerate adverse external conditions like network issues or database problems. “Only half of programming is coding. The other 90 % is debugging”. [Programmer humour]
Fault avoidance in software development
Make it easy to do the right thing. Make it difficult to do the wrong thing. Make it almost impossible to do the catastrophic thing.
It is often argued that all software faults are design faults [2]. We can reduce the number of bugs introduced during design or development by using Fault avoidance techniques described below. “60-65 % of software faults originate from incomplete, missing, inadequate, inconsistent, unclear requirements” [1]. Typical requirement specification describes what the system should do, but doesn’t specify what the system should do in case of exceptions. All deviations from the “happy path” should be clearly documented in the Use cases. As a side effect this also results in more consistent estimations. Code smell is the major source of bugs. Switch statements without a default often result in unexpected behavior. Long if-elseif-elseif constructs often compare apples with oranges and become hard to read creating an opportunity to introduce more bugs that are hard to catch. All such smells should be listed in the Code Review checklist.
Design principles, software testability, and reliability go hand in hand. By designing the system according to SOLID principles, Clean Architecture, and many others – not only result in a testable system, but also make it difficult to introduce errors later. By paying a small overhead of developing extra interfaces and classes we achieve a modular system that is easy to read and to spot any potential errors at review time. Spaghetti code is the primary reason the code becomes fragile. Separation of concerns is an important technique to reduce code coupling and its fragility. Rather than doing everything in a single class all actions should be split across dedicated services as seen in Listing 1. Minimizing the amount of information passed to corresponding services is a big step forward to reduce coupling and improve testability (Listing 1).
switch ($paymentType)
{
…
case self::PAYMENT_TYPE_PAYPAL:
if (!$this->paymentsService->paypalPayment( $this->order_id, $this->order_total ))
return SYSTEM_ERROR;
break;
default:
return SYSTEM_ERROR; // Missing default is a code smell
}
if (!$this->orderService->orderPaid( $this->order_id, $paymentType ))
return SYSTEM_ERROR;
if (!$this->shipmentService->shipOrder( $this->order_id ))
return SYSTEM_ERROR;
Information hiding is a technique making code easier to use, but difficult to misuse. Hiding class constants is a good place to start for two reasons: first, another developer doesn’t have to know my domain and know what constants the class uses and why; second, he won’t have an opportunity to pass the wrong parameters or call methods in the wrong sequence. This is especially important for PHP which doesn’t have enum type, so a developer may pass an irrelevant constant and break the state. Public convenience methods hiding the implementation make it [almost] impossible to misuse this class and isolate the collaborators from any change in its implementation – see Listing 2. Convenience methods pass() and shoot() – which are simple wrappers for private action() method – do hide the implementation and don’t require any domain knowledge to use them (Listing 2).
class FootballGame implements FootballInterface
{
private const PASS = 0;
private const SHOOT = 1;
public function pass()
{
return $this->action(self::PASS);
}
public function shoot()
{
return $this->action(self::SHOOT);
}
private function action(int $type)
{
// ...
}
}
Especially state machine implementation should definitely be encapsulated within a single class, hide everything, and allow state transition only using its public methods performing internal consistency checks that are strongly validated by unit tests. Number of bugs and security vulnerabilities produced by developers can be also reduced by training. This is especially important for developers working on mission-critical tasks. Training for the above topics and secure software development methodologies is a good place to start. Holding annual refresher sessions for each training is a great idea to keep everyone in check. Additionally, people without proper training should have limited or no access to sensitive modules.
Nowadays assertions are only being used in Unit tests and their importance is utterly underestimated. Especially in PHP, where could you use assertions? Loading configuration or environment variables is the right place. Sanity check using assertions should be performed at startup for all hard-coded configurations, library compatibility, server configuration, and other critical settings. Obviously this should not be done during runtime or any time after the startup. Did someone say such assertions should be done in Unit/Integration tests? Well, yes. But that doesn’t cover for inconsistency in the Staging or Production server configuration or environment. Who wants to debug deployment bugs? Anyone familiar with situation when system crashes in production, but developers say: “Everything works on my machine”?
Enable PHP warning messages and strict_types in the Development server, definitely on developer’s machine! (Who uses Docker images for development environment consistency?). Most bugs emit warnings. And these can be easily spotted by developers when display_errors is true. Redirect these logs to your log monitoring system to catch unseen PHP errors and warnings in Ajax calls that are silently suppressed in the JavaScript console. NOTE: Strict types are declared on a per-file basis, so older libraries and old code will still work. Have you ever spent time debugging the PHP code? Well, in most cases PHP warnings would have done the job for you!
Fault tolerance
Robust software will be able to indicate the fault correctly. Fault-tolerant software will continue working to provide services as expected. Fault-tolerant system should be able to detect the error, still work after the error, and recover from the error. Fault detection techniques need to be used to detect the error and identify its source. Typical methods used are: checksum validation, parse errors, exceptions, and additional sanity checks. Sample sanity check would be validating the order state after the transaction: what if order ends up in an unexpected state due to some error? In mission critical systems such options should always be considered and all important steps covered with dynamic sanity checks.
The detected errors should be isolated to prevent propagation of the error. To continue the above example: the application should freeze the order to prevent further unexpected operations caused by its invalid state. The application may continue working in a degraded state and wait for recovery. In the above example, the application may display order status as “Waiting for approval” and wait until a watchdog application or developers trace and fix the error. All other modules unaffected by this order should continue working as usual. Once the error is fixed application should notify all relevant modules and resume operations.
Repairable system is able to handle and recover from the error state. Check the Listing 1 where the payment method executes three different actions that may fail due to internal or external conditions. While failure of the first payment step is simple to handle, the orderService and shipmentService failure may result in an inconsistent state. We can either display “An error occurred, please try again” message and have user endlessly retry the transaction until all steps succeed (need duplicate transaction protection), or create a repairable system that will display “Order is being processed” message and process these operations asynchronously. In the latter scenario any failing transactions may be retried endlessly or even processed manually, but this will result in overall smooth, error-free buying experience from the user’s perspective.
A highly reliable system can be achieved by redundancy. N-modular Redundancy is the most popular technique used in cloud services to handle transient errors such as memory, network, or power outages. Rule of thumb is to avoid any single point of failure – each mission critical system should be redundant. Nevertheless, the redundancy implementation using copies of the same software fails to prevent failures caused by software bugs – because the same bugs will be replicated across the redundant server farm. Different software implementations should be used for critical systems. For example Database failure may be masked by a data Cache, web service failure can be masked by an HTTP cache – data may be a little stale, but the systems will continue operation until the database is back. User may be additionally notified about the temporary issue, but at least she will be happy that app is still usable and responsive. Additionally, mobile or web apps can implement a local cache for data and configuration making them even more fault-tolerant (Figure 1).
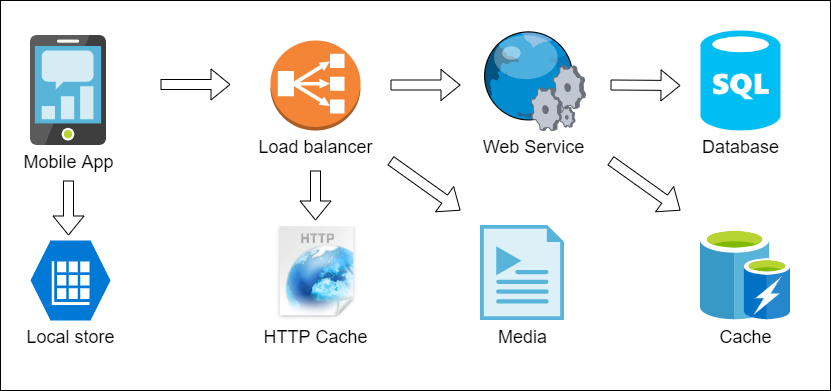
Figure 1: Typical fault-tolerant system implementation
Tools and Techniques
Code Reviews can catch up to 60 % of the bugs [3]. However, widely used Peer Code Reviews are no panacea, since while reviewing a small portion of code that changed you can’t predict the consequences on the rest of the system, especially if you don’t know the rest of the system very well. We need to understand the context where the changed code is used in order to identify the bug. We also need to read the requirement specification to understand if this code actually does what it is supposed to do. Hence, typically, peer Code Review is most useful at improving the code quality and catching obvious mistakes like forgetting a second ‘=’ sign in comparison, which even senior engineers do.
Formal Code Review, on the contrary, is intended to validate the code and it’s compliance with the specifications as a whole. Although formal review is considered to take an enormous amount of time there are methods to run it faster and still achieve a similar level of efficiency. In the formal review the developer will show to the reviewers (typically the architect) all changes and explain reasons according to the system specification or task description. The key point here is that architect will walk through the specific scenarios from top to bottom and see the system as a whole. Reviewer can trace the edge cases and exceptions, audit the system for fault-tolerance, and check which measures have been taken to prevent failures.
Hewlett-Packard’s code inspection study showed that “only 4 of the 21 defects found during Code Review could conceivably been caught during a test/QA phase” [4]. Unit Tests and Integration tests are indispensable, but rather for validating the code for compliance with the specification and less for bug finding. The average defect detection rate is only 25 percent for unit testing, 35 percent for function testing, and 45 percent for integration testing. In contrast, the average effectiveness of design and code inspections are 55 and 60 percent [5].
Each new feature increases complexity and introduces new bugs. Fixing problems doesn’t make the software more reliable – any bugfix may cause 10 other bugs! All automated tests are intended to catch regression. Hence any bugfix should have a test case of its own – both to verify the bug is fixed and stop the same bug from popping up again and again later! Needless to say the bug’s test case should be committed and reviewed together with the bugfix itself so reviewer can verify if the bug has actually been fixed. Does the case when “hotfix didn’t fix the bug” sound familiar? Speaking of which, bug’s test case should be written before the bug is fixed – we want to make sure the test case actually catches the bug properly – only then we can rest assured the bug has actually been fixed (Figure 2).
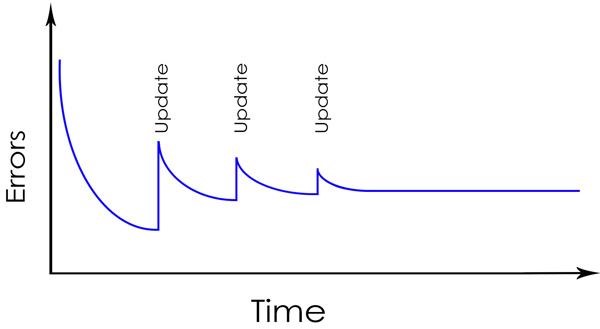
Figure 2: Software reliability graph
Many bugs in PHP code go unnoticed due to lack of strong typing and a static compiler. Modern code linters and a good IDE can detect and prevent such issues automatically. Check Psalm, Phpstan, Phpstorm, and others for more details.
Conclusion
“We are very good at building complex software systems that work 95 % of the time” says NASA. However, getting from 95 % reliability to 99 % reliability is achievable simply by using proper tools. Applying fault avoidance and fault tolerance techniques will allow you to achieve even higher reliability levels.
Links & Literature
[1] Elena Dubrova – Lecture notes, https://people.kth.se/~dubrova/FTCcourse/LECTURES/lecture2.pdf
[2] N. Storey, Safety-Critical Computer Systems. Harlow, England: Addison-Wesley, 1996.
[3] Shull et al, What We Have Learned About Fighting Defects https://kevin.burke.dev/docs/shull_defects.pdf
[4] Frank W. Blakely, Mark E. Boles, Hewlett-Packard Journal, Volume 42, Number 4, Oct 1991, pages 58-63.
[5] Steve McConnell, Code Complete: A Practical Handbook of Software Construction, Microsoft Press, 2004.




