
Whether they’re configuration files, for data exchange between client and server, or for object serialization, text-based formats like XML, JSON, YAML, and co. are ubiquitous for developers. But it’s not just developers confronted with these formats. Software users, support specialists, administrators, and consultants also work with files and data streams in these formats for configuration or error analysis. Although their basic concepts are relatively easy to understand, not everyone can easily find their way around the sometimes extensive rules.
Even advanced developers don’t know all the lengthy specification details by heart. The 84-page long YAML specification is an example of this, along with the XML specification. If a format also offers alternatives for how to implement something, even experts start wondering. For example, YAML offers nine different ways to write a multiline string [1]. And anyone who has defined an XML format is guaranteed to have had a discussion or two about whether a value should be written as an element or as an attribute.
IPC NEWSLETTER
All news about PHP and web development
Also writing documents in these formats isn’t easy for everyone. Even if programming languages train developers to write many special characters, ten-finger typists are especially aware that special characters can significantly influence writing speed. That’s why some German developers switch their keyboard layout to the US layout in order to type special characters more easily.
Another aspect is the issue of readability. A JSON document that’s minimized down to one line is only meaningfully readable, if a developer has tools for formatting or better rendering. How often are documents with sensitive data put into Pretty Printer web pages without knowing where the data is sent? And someone has likely already come across an XML document displayed in Internet Explorer.
The question is, can we find an alternative data format to XML, JSON, and co. that:
- has reduced its set of rules to a minimum, yet remains functionally equal,
- is easy and fast to write,
- is readable even without special tools and,
- is easy to understand and intuitive, even for non-experts?
The Simple Markup Language, or SML for short, targets exactly these requirements. In the following sections, we’ll take a look at SML’s basic concepts and notation, and at the end, we’ll highlight some potential application areas.
The first example
To get started, let’s consider the following example of an SML geodata format describing a prominent geographic point. In this case, it’s a Seattle city landmark, the Space Needle observation tower.
PointOfInterest City Seattle Name "Space Needle" GpsCoords 47.6205 -122.3493 # Opening hours should go here End
You can see that SML is a line-based format. The first line that starts the document gives an indication about its content. The second line defines the city that the point of interest is located in and represents an attribute. The attribute name and the attribute value are separated by several spaces, and there isn’t a special character like a colon or an equals sign between them. Line three contains the landmark’s name. In contrast to line two, the attribute’s value is written in double quotes. These are written because the name itself contains a space. The next line represents the point’s GPS coordinates. Attributes can contain several values. As in this case, these are separated from each other with spaces or other whitespace characters and are written one after another. The second to last line contains no information other than a comment starting with a hash that goes to the end of the line. The last line contains the word End and closes the document. You’ll notice that SML gets by with relatively few special characters. Even someone who isn’t an expert can easily type this text and it wouldn’t take them very long.
XML, JSON, and YAML
Now, let’s compare the SML document with an XML document containing the same information (Listing 1).
<?xml version="1.0" encoding="UTF-8"?> <PointOfInterest> <City>Seattle</City> <Name>Space Needle</Name> <GpsCoords lat="47.6205" long="-122.3493"/> <!-- Opening hours should go here --> </PointOfInterest>
The first thing to note is that this is just one way that information from the SML example can be mapped to XML. For example, the GPS coordinates could be represented as sub-elements instead of attributes, or as InnerText separated by special characters, which is later split into two components. The developer’s preference influences which option they choose. XML is a powerful markup language that can be used to represent data in a structured way and format text in the true sense of a markup language. However, in this example of a structured dataset, we can see that many more special characters are used. Attribute values must be written in double quotes and closing tags have the same name as opening tags. If we held a small typing competition without any special tools, the person typing SML would probably finish first. Besides the XML declaration in the first line, and typing the comments, XML’s main hurdles can be points such as namespaces, or specification details. For example, are line breaks allowed in attributes? Can attributes be commented out? And can you enter the syntax of a CDATA block from your head?

For comparison, let’s consider another widely used standard: the JavaScript Object Notation. In JSON, our geodata example would look like this:
{ "City": "Seattle",
"Name": "Space Needle",
"GpsCoords": [47.6205, -122.3493],
"_comment": "Opening hours should go here" }
JSON is a simple data format that’s very popular, especially due to its interaction with JavaScript in the browser. It’s used for client-server communication, for custom data formats as an alternative to XML, as a configuration format, and more. It builds upon the use of double quotes, colons, commas, square brackets, curly brackets, and some keywords to describe data structures and types. String values must be written in double quotes, and C-compatible escape sequences allow a JSON document to be written entirely in just one line. A forgotten or superfluous comma at the end leads to a syntax error. Comments that can be written in JavaScript with // and /* */ aren’t allowed in the JSON standard. For serialization formats, this might not be a big deal. But for formats where you comment in and out parts, such as configuration files, this can be impractical and can lead to some workarounds or alternative formats. These range from key-value pairs—where a special prefix in the key identifies the pair as a comment—to preprocessors that filter out comments before parsing the document, to formats like Hjson [2] and JSON5 [3]. Unlike SML or XML, the JSON root element doesn’t have a name. So by default, a JSON document doesn’t have an identifier that gives an initial hint about the document’s contents.
YAML is a common alternative to JSON. YAML combines JSON’s syntax with a special character reduced notation based on indentation rules similar to Python. In YAML, our geodata example looks like this:
City: Seattle Name: Space Needle GpsCoords: [47.6205, -122.3493] # Opening hours should go here
Just like SML, YAML supports single-line comments beginning with a hash. The GPS coordinates are written like a JSON array, but they can also be written individually in multiline notation, preceded by a hyphen and at least one prefixed whitespace. A colon—also followed by at least one whitespace character—is used to separate keys and values. Although YAML appears simple at first glance, its pitfalls lie in its many special rules, which can be quite complex [1]. If you prefer using tabs for indentation, you’ll be disappointed. In YAML, using spaces is mandatory.
In general, the more special characters are used and the more extensive the ruleset is, the more difficult it gets for non-experts and experts alike. The more rules there are, the more can go wrong, and the format’s robustness suffers. Therefore, the ruleset in SML is reduced to a minimum, as is the amount of special characters used. This makes the format robust, simple and fast to type, and easy to learn. Now, let’s take a look at how exactly SML works.
Simple Objects
Before we take a closer look at the Simple Markup Language’s rules, let’s consider the data structure behind SML documents. An SML document represents a hierarchical data structure called a Simple Object. This hierarchical data structure is built from two kinds of nodes: elements and attributes. A simple object has strictly one root element. The root element can contain more elements or attributes. Elements are used for grouping, while attributes contain the actual data in the form of string values. Both kinds of nodes are named. Elements are named groups of child nodes, and attributes are named string arrays.
Figure 1 shows our SML geodata example as a hierarchical data structure. The Simple Object consists of the root element PointOfInterest. Three attributes are subordinate to this root element. The first two attributes—City and Name—contain just one value each. The third attribute—GpsCoords—contains two values.
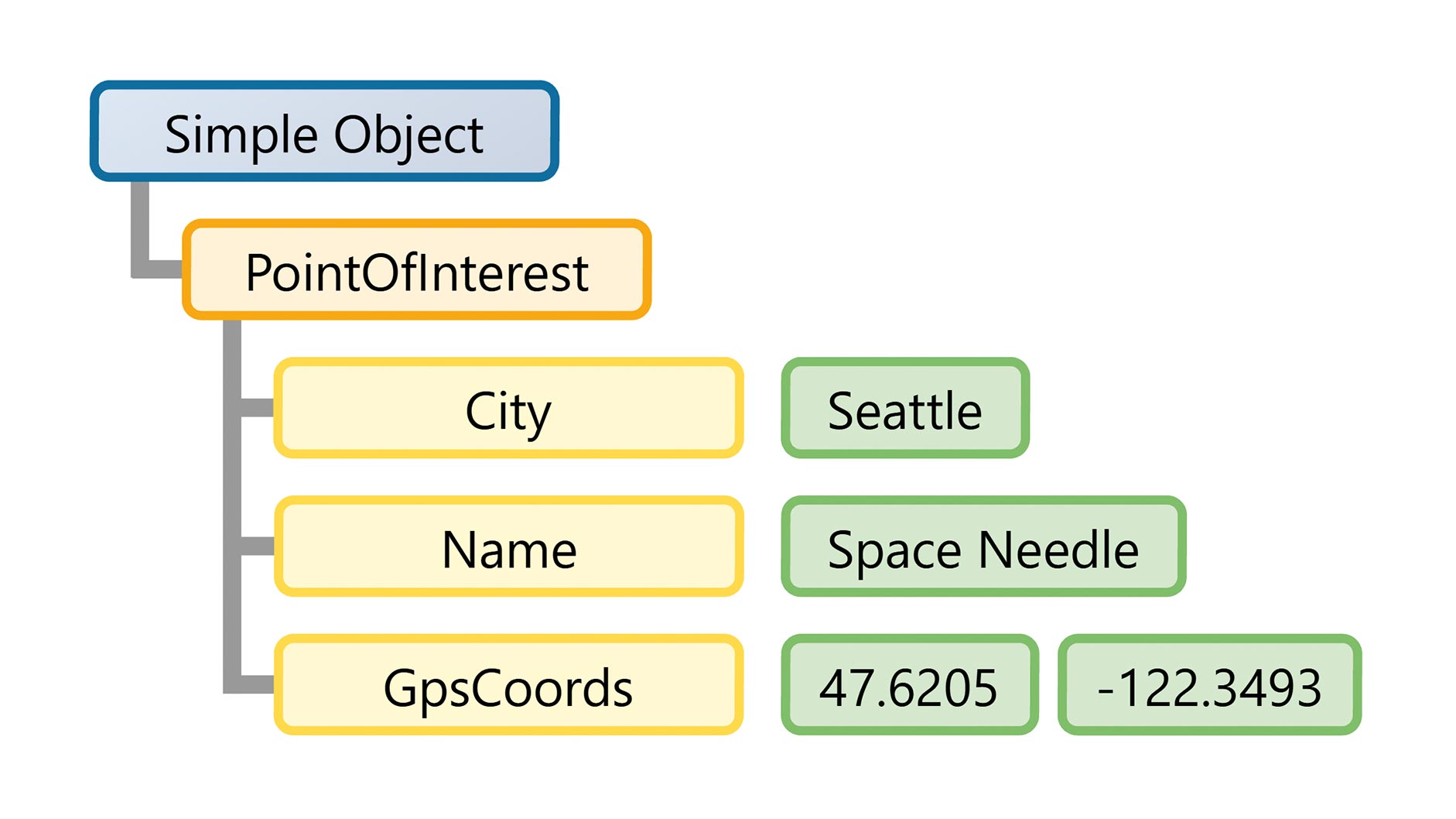
Fig. 1: Visualization of the SML data structure in the geodata example
Attributes must contain at least one value, but they can also contain empty strings or null values. An element’s child nodes are ordered and can have identical names. For example, it’s possible to subordinate several attributes that have the same name to one element. Elements don’t necessarily have to contain nodes—they can be empty.
There are no restrictions concerning node names, except that you cannot use null values. All Unicode characters are allowed and the character order can be randomly chosen. It is important that names are case-insensitive, meaning that upper and lower case characters are not considered. So in our example, we could write the City attribute entirely in lowercase or the Name attribute entirely in uppercase and it would make no difference. Later, we’ll take a closer look at why these properties are important in an easy-to-write format.
Serialization of Simple Objects
Now that we know the data structure behind SML documents, let’s look at their serialization. The simplest form of serialization for a machine is converting to binary format. Then, no parser is needed for reading and the bytes only have to be processed according to a given schema. This form of serialization is machine-friendly, but isn’t human-friendly at all. Alternatively, serialization to a common text-based format like XML or JSON is also possible. But since these are usually case-sensitive or, like XML, have naming restrictions, mapping is tedious and needlessly bloats the resulting documents.
IPC NEWSLETTER
All news about PHP and web development
This is where the Simple Markup Language comes in, offering the textual representation of a Simple Object reduced down to the minimum. The basic concept is simple. It is based on the approach that in a textual representation, two text entries with an unknown length must always be separated by at least one character. For this, common formats use colons, commas, equal signs, and other special characters. But why don’t we just use a space and the Enter key? A line break can be represented with just a single character and a space is enough of a visual separation between two values. We’ve therefore arrived at a line-based format.
But how do we distinguish between the two kinds of nodes without marking them with special characters? The trick is simple. Consider each line as a set of values separated by a single or multiple connected whitespace characters. If the line contains just one value, it’s an opening or closing element. If it contains at least two values, then it’s an attribute. If the line doesn’t contain any values, it’s an empty line that doesn’t contribute to the Simple Object’s content.
Whitespace-separated values (WSV)
This concept is comparable to a CSV file (Comma-separated values). Here, values are separated from each other with a separator like a comma or a semicolon. In the case of SML, the separators are a group of characters—whitespace characters. This includes tabs and other Unicode whitespace characters, as well as the space character. So, one line in an SML document is a WSV line and the entire document is a WSV document [4]. If a value itself contains whitespace characters, then we simply enclose it with double quotes. Let’s take a look at the other special rules (Listing 2).
ValueWithSpace "Hello World" ValueWithDoubleQuotes "Hello ""World""" EmptyString "" Null - OnlyOneHyphen "-" MultilineText "Line 1"/"Line 2" ValueWithHash "#This is not a comment"
If a value contains a double quote character, then it must be written in double quotes and the character must be replaced by the escape sequence “”. An empty value is represented by two double quotes directly following each other and a null value is represented with a hyphen. In this convention, a single hyphen as a value must also be written in double quotes in order to differentiate it from the null value.
Concerning multiline values with line breaks, SML takes the following approach: To obtain a truly line-based format, the linefeed line break character is replaced with the escape sequence “/”. The advantage is that an attribute line can be in one line, even with multiline values. The document’s structure is still recognizable. Another advantage of this approach is that a self-written parser that splits the document string into its lines with a simple string split call won’t return wrong results. In the example, we see how a two-line value is written in one line.
Since the hash sign in SML marks the beginning of a comment, a value containing the hash sign must also be written in double quotes. And with this point, the list of rules is already done. No further characters need to be replaced by escape sequences. The result is that many values, even those with exotic special characters, don’t need double quotes.
The End
We’ve already defined that an SML line with only one value represents an opening or closing element. We need a special keyword to differentiate which of the two cases we’re dealing with. The most obvious solution is to use a keyword that’s been used in line-based programming languages for decades: the keyword End. This is used by default. But SML goes a step further and allows for arbitrary values as end keywords. The reason is that an SML document doesn’t need to be written in English, it can also be written entirely in a different language. For example, the SML document in Listing 3 is written in German.
Vertragsdaten
Personendaten
Nachname Meier
Vorname Hans
Ende
Datum 2021-01-02
Ende
To make this work, when the document is loaded, the parser goes to the end of the document, determines the end keyword, and begins interpreting the lines from the top. This concept allows for comprehensive localization and completely automatic reading without having to specify what the end keyword is.
In contrast to the Simple Object, this concept imposes a restriction on naming elements. An element cannot have the same name as the end keyword, or else the hierarchical structure won’t be recognized correctly. Otherwise, any name can be chosen, besides the null value. Here, the same notations apply as for values. The following example shows an SML document whose root element and child attribute each contains spaces in their names, and so they must be written in double quotes.
"My Root Element" "My First Attribute" 123 End
The name for elements and attributes must not be null to make processing in programs more robust. Another reason is the possibility that SML documents can be minimized. We’ll take a closer look at that now.
Minimization
In SML, indentations help you better identify the hierarchical structure. Listing 4 shows an example of a game’s configuration file with two child elements.
# Game.cfg
Configuration
Video
# Set the resolution settings here
Resolution 1920 1080 #Alternativ 1280 720
RefreshRate 60
Fullscreen true
End
Audio
Volume 100
#Music 80
End
End
Unlike YAML, indentation isn’t mandatory in SML and all whitespace characters can be used as you wish. Attribute values don’t need to be separated from the attribute name by only one whitespace character and the following values as well can be indented arbitrarily. Comments are also possible everywhere. For example, in the SML configuration file, a comment was left behind the Resolution attribute and the Music attribute was commented out completely. Completely empty lines or lines with only a comment are possible.
This formatting freedom contributes to SML’s robustness and usability. But for a machine, indentations and comments aren’t important and can be removed. A document reduced to the bare minimum makes sense, especially in the context of client-server communication, where data sizes play a large role. JSON also offers the possibility of minimization. Here, whitespace is completely removed and the document is reduced to a one-liner. This is good for data size. But readability suffers and it leads to the previously mentioned use of Pretty Printers. On the other hand, SML is readable even when minimized, since it preserves line breaks. It might seem counterintuitive to some people, but keeping the line breaks does not hinder minimization, since it only takes one character for a line break. Listing 5 shows the configuration example minimized.
Configuration Video Resolution 1920 1080 RefreshRate 60 Fullscreen true - Audio Volume 100 - -
All comments have been removed and indentation is missing. Now, values and attribute names are only separated with a single space. The end keyword has been replaced by a null value and when serialized, it is represented with only a hyphen. Since element names must not be null, no name collisions can happen here. Minimization is therefore always guaranteed. Even without Pretty Printer, the document’s contents are easily recognizable.
Encoding
If you store SML documents as files or serialize them as byte arrays, keep in mind that regarding encoding, SML documents are ReliableTXT documents. ReliableTXT [5] is a convention that specifies how text files are encoded, decoded, and interpreted. The specifications are chosen so that common encoding problems can be avoided. This is done with the mandatory writing of an encoding preamble (a short byte sequence) which clearly identifies the encoding used. The preamble means that we don’t need to guess the used encoding and instead, a reliable reading is possible. ReliableTXT limits the potential encodings to just four Unicode encodings. These are UTF-8, UTF-16 in little- and big-endian, and UTF-32 big-endian. The BOM (Byte Order Mark) must be written for all of them. If it’s left out, an SML loader must indicate an error and must not read in the document. This might sound strict, but it’s necessary in order to enable reliable reading. It’s important to know that the preamble isn’t part of the text content.
ReliableTXT also uses a different name for the byte order. The little-endian order is called reverse and the big-endian designation is left out altogether. This is an alternative mnemonic for remembering the byte order. It’s based on the fact that in languages like English or German, numbers are written in big-endian—the first digit has the highest value. For such languages, big-endian is the normal case and little-endian is reversed notation.
IPC NEWSLETTER
All news about PHP and web development
When it comes to line breaks, ReliableTXT also walks its own path. The Unicode Standard knows seven different characters that can be interpreted as line breaks. ReliableTXT is limited to a single character for a line break—the line feed character. But ReliableTXT files are not POSIX/Unix text files because the lines aren’t terminated with the linefeed character—they are separated by it. This is similar to the concept of Windows text files, but without using the Carriage Return character. Since the Carriage Return character is considered to be whitespace in an SML document, you won’t run into any problems if an SML document is ever written with Windows line breaks.
Possible uses
SML is a universal format and can be used in a wide variety of areas. SML is especially easy to use in the field of structured data. Possible application areas are formats for configuration and localization, 2D and 3D graphics formats or UI, geodata, multimedia, and manifest formats. A simple format for recipe instructions is possible as well as complex data structures. Using SML is especially useful if a file needs to be viewed or directly modified in the text editor—for instance, if there’s no program with a visual interface yet. SML can also be used for easily creating files for other programs. You can create a media playlist like the following with any program.
Tracks Track Song1 /storage/sdcard0/Music/Song1.ogg Track Song2 /storage/sdcard0/Music/Rock.ogg Track Song3 https://www.example.com/Pop.ogg End
One particular strength of SML is the combination of hierarchical data structures and tabular data. Since attributes can contain multiple values, it’s easy to embed tables in SML documents. In the table’s first column, there is a primary key that cannot take null values. The value can be used directly as an attribute name. The example in Listing 6 shows an SML document containing two embedded tables.
Tables
Table1
FirstName LastName Age PlaceOfBirth
William Smith 30 Boston
Olivia Jones 27 Austin
Lucas Brown 38 Chicago
End
Table2
City State
Boston Massachusetts
Austin Texas
Chicago Illinois
End
End
The formatting flexibility allows you to use tabs or spaces to present data in a more visually arranged manner. This document can be easily typed into any text editor without having to use a single special character.
Client-server communication and remote procedure calls also profit from SML. Where once an XML file was transmitted with AJAX and then later JSON was used, now SML documents could be exchanged between the machines. Size-wise, SML is at least equivalent to JSON and can even achieve smaller sizes without compression.
Conclusion
At the beginning of this article, we asked if we can find an alternative data format to XML, JSON, and co. It needs to have a reduced, minimal set of rules while also staying functionally equal, is simple and fast to write, as well as readable, easy to understand, and intuitive even for non-experts. Of course, the last point is purely subjective because everyone decides for themselves what is understandable and intuitive. The first point depends on the purpose that a format is used for. If a text will be formatted in a very finely-granular way, then a language like XML or Markdown is likely a good choice. But when it comes to purely structured data, SML is in no way inferior to widely used standards like XML, JSON, and YAML. Especially when it comes to manually modified documents or their display in text editors, SML scores points. It stands out because of its simple notation. People who type with ten fingers will likely find the format particularly pleasant, as it’s faster to type due to the reduced amount of special characters and case insensitivity. Regarding the amount of rules, SML has reached a minimum that could likely only be exceeded by getting rid of some functionalities.
Other than that, all that’s left to say is: Just try it out. You can test out SML online directly in the browser (See box: “Just try SML in the browser”) [6]. Reference libraries are available for the top ten TIOBE languages such as Java, PHP, C#, JavaScript, and Python [7] and there are many tutorials for getting started [8]. With this in mind: happy SML typing!
Just try SML in the browser
Website: open www.simpleml.com
Select the Try SML Online item
Enter the SML document, parse it, and display it as a collapsible and expandable node representation
Links & Literature
[1] https://www.arp242.net/yaml-config.html
[4] https://www.whitespacesv.com
[5] https://www.reliabletxt.com
[7] https://github.com/Stenway
[8] https://www.youtube.com/channel/UCSVt-9JcnxfTFnztnLEQQug




